Code Editing in Copilot Arena
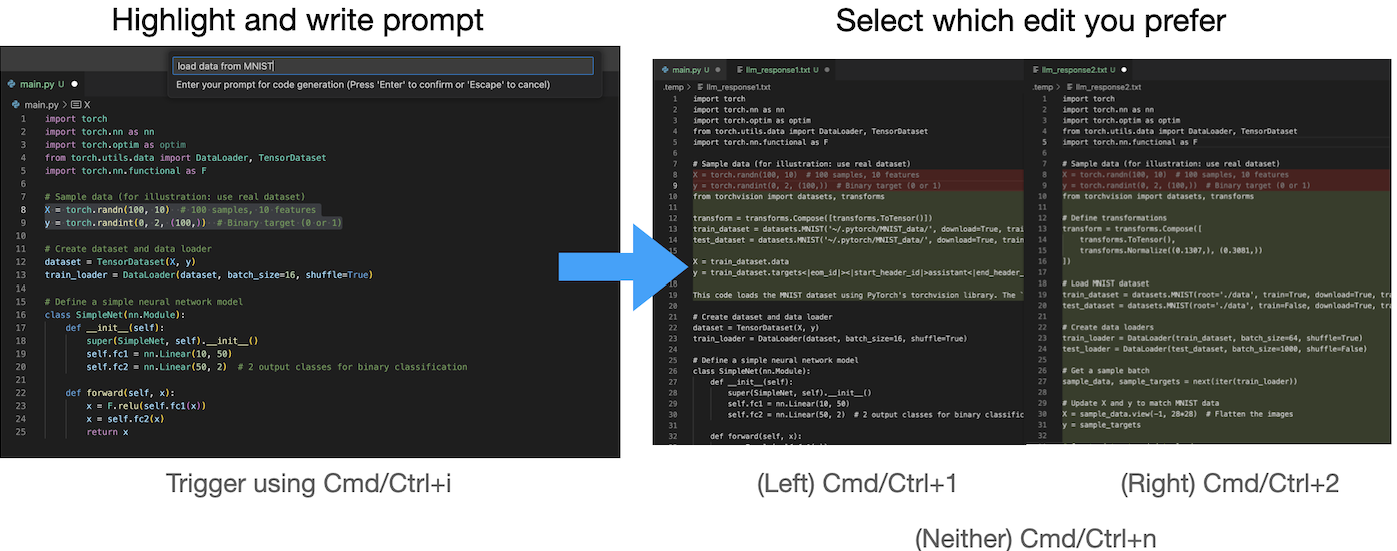
Copilot Arena enables not only paired code completions but also paired code edits as well. Unlike code completions—which automatically appear after short pauses—code edits are manually triggered by highlighting a code snippet and then writing a short task description.
Copilot Arena's Code Editing Leaderboard and Insights
Contributors:
Wayne Chi
Valerie Chen
Anastasios N. Angelopoulos
Wei-Lin Chiang
Naman Jain
Tianjun Zhang
Ion Stoica
Chris Donahue
Ameet Talwalkar
Introduction
AI coding assistants are no longer limited to providing simple code completions, frequently providing the ability to directly edit code as well. Copilot Arena is no different: Copilot Arena enables not only paired code completions but also paired code edits as well. Unlike code completions—which automatically appear after short pauses—code edits are manually triggered by highlighting a code snippet and then writing a short task description. In Copilot Arena specifically, two suggestions (presented as code diffs) are provided and the user is able to vote between them.
To date, Copilot Arena has been downloaded over 8.5k times on the VSCode Marketplace! We recently released the Copilot Arena live leaderboard for code completions on lmarena.ai and now the code edit leaderboard, which has 3K votes across 6 top models.
In this blogpost we will cover:
- Initial leaderboard and results: Our preliminary results for the code edit leaderboard and analysis of model tiers.
- Code edit usage: Analysis of how users request code edits, including the distribution of prompt length and highlighted context length and an analysis of the types of prompts that users tend to write.
Initial Leaderboard and Results
As an initial set of models, we selected 6 of the best models across multiple model providers that include both open, code-specific, and commercial models. To ensure a fair comparison between models, we do the following…
- We randomize whether models appear at the left or right panel along with which models are paired for each battle.
- We show both completions at the same time. This means that a faster model completion needs to wait for the slower model.
- We set the same max number of output tokens, input tokens, top-p, and temperature (unless specified by the model provider).
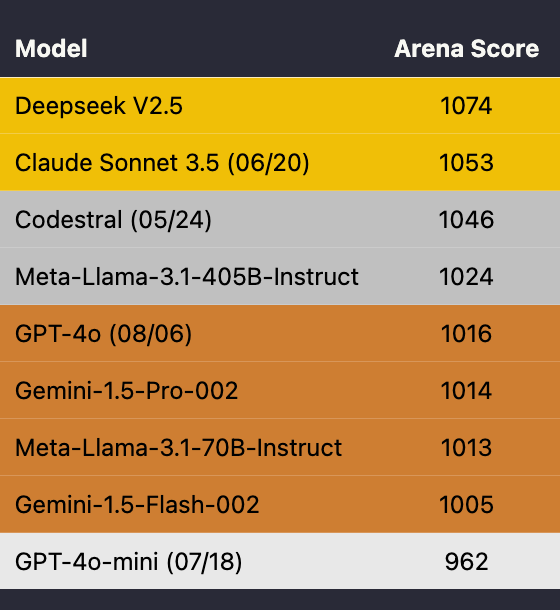
^ Table 1. Elo ratings and median latency of six popular models based on over 3K votes. We color rows based on tiers determined by confidence intervals. Each model has at least 1K votes.
Table 1 presents the current code completion leaderboard and stratifies them into tiers. Here are our main takeaways:
- The clear winner is Claude 3.5 Sonnet in terms of Arena Score.
- While some of the models in the middle fluctuate, we have generally observed that Llama-3.1-405b is the least preferred by users by far of the models we evaluate, losing a majority of the time to all other models (see Figure 2).
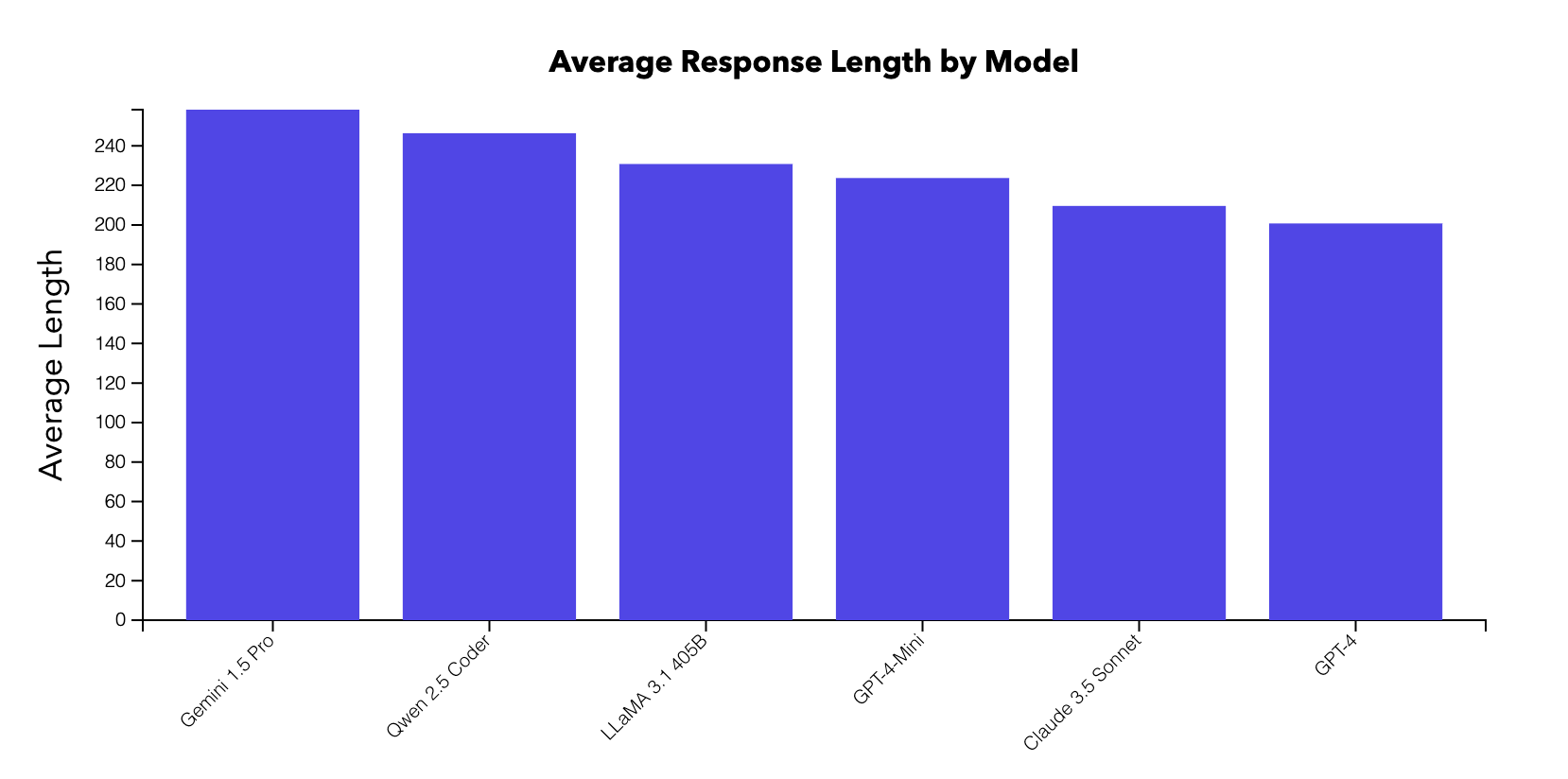
- We inspect whether response token length per model is correlated with preferences. Interestingly, we tend to see that people tend to prefer shorter responses. This is the opposite effect compared to what has been observed in prior work where people tend to prefer longer responses. This may however be correlated with model quality.
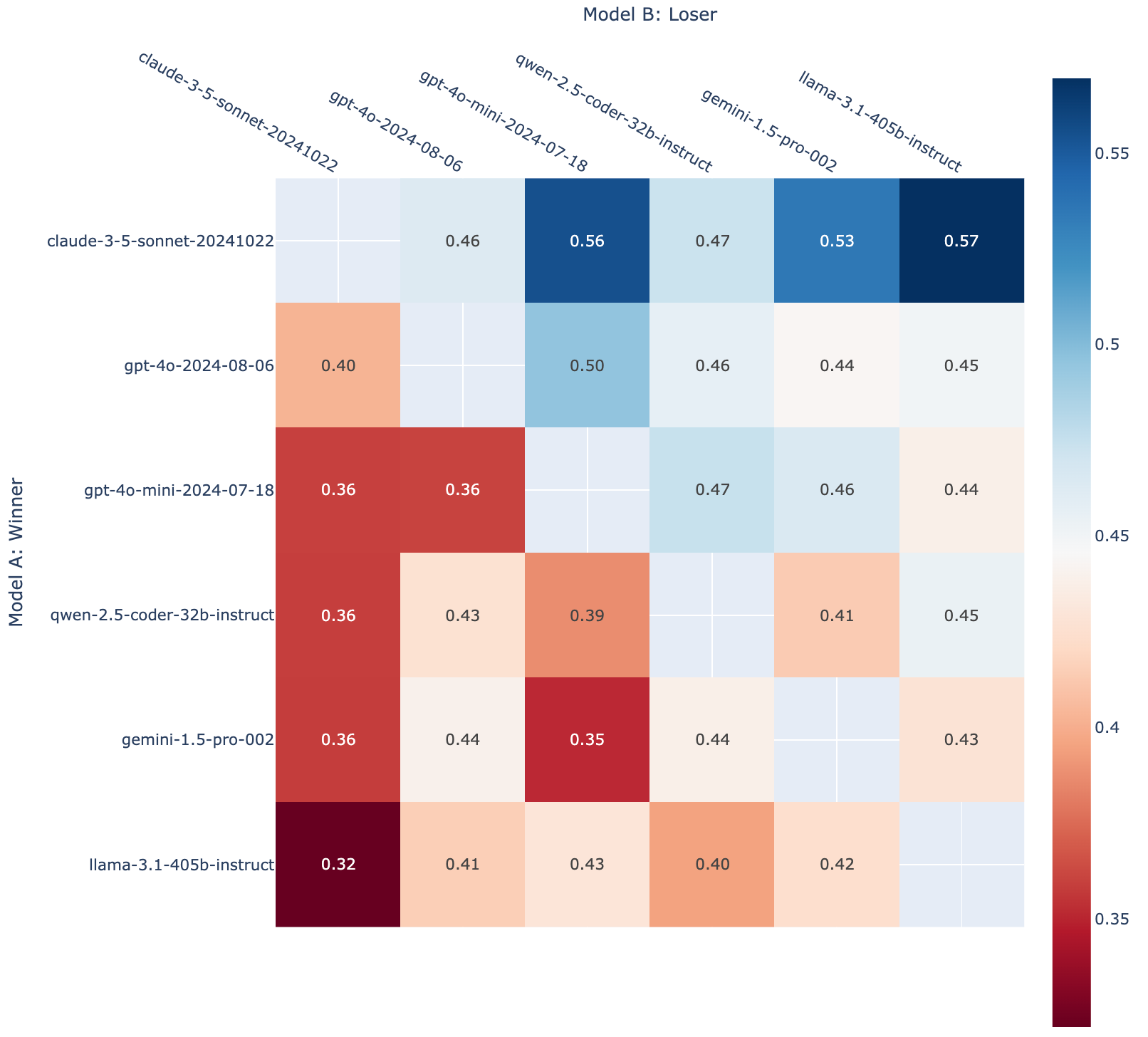
We follow the same leaderboard computation as the latest version of Chatbot Arena, which is based on learning Bradley-Terry coefficients that minimize loss when predicting whether one model will beat the other. Please check out this blog post for a more in-depth description.
How do people use code edits?
For general information about how people use Copilot Arena, check out the first blogpost. Here, we will focus on code edit usage.
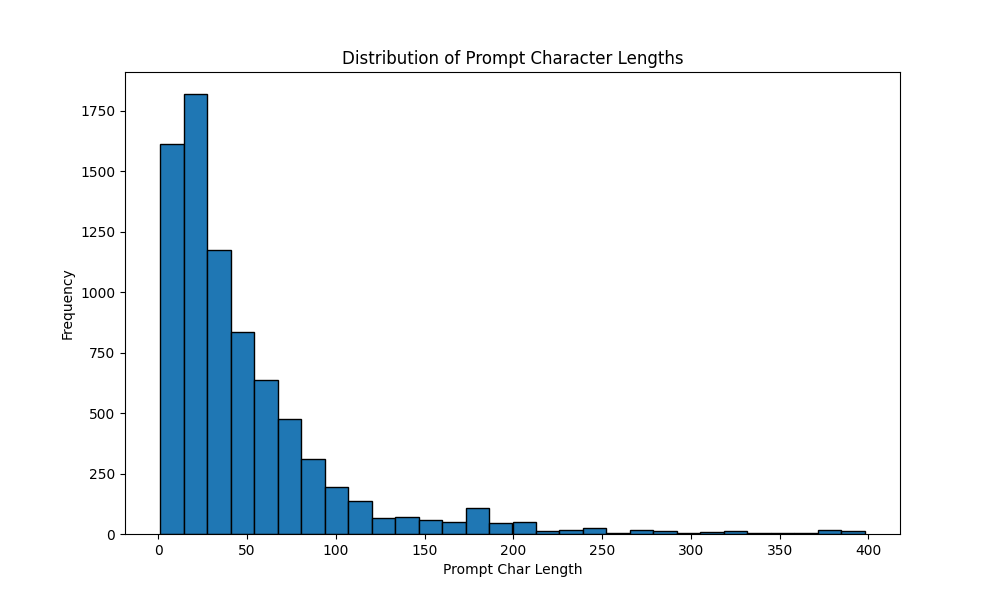
How long are the prompts that people write? We find that the median prompt length is 34 characters and mean is 139 characters. Most are fairly short and thus depend on the context that is highlighted. In comparison to the chat messages sent by users in Chatbot Arena, user prompts for inline edits tend to be much shorter. The model must instead mostly focus on test the model’s ability to infer user goals based on the context (e.g., the highlighted code snippet).
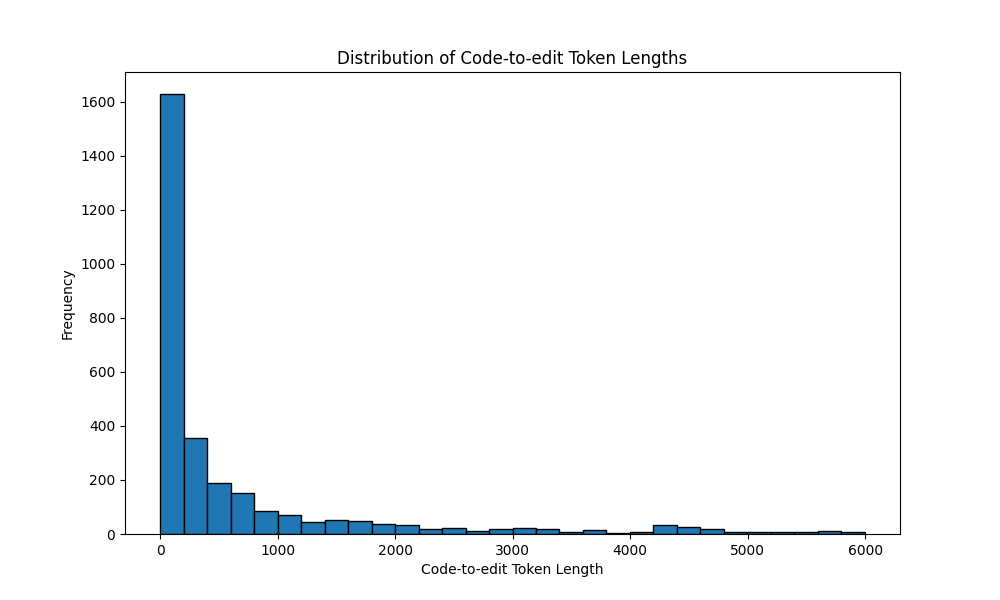
What context lengths are we looking at? We look at the distribution of code-to-edit token lengths, as computed by the number of highlighted tokens. The median is 138 tokens and the mean is 647 tokens. While there are some outliers, this indicates that most people are highlighting targeted portions of code for edits as this is much shorter than the full file length which is typically closer to 4.5k tokens on average.
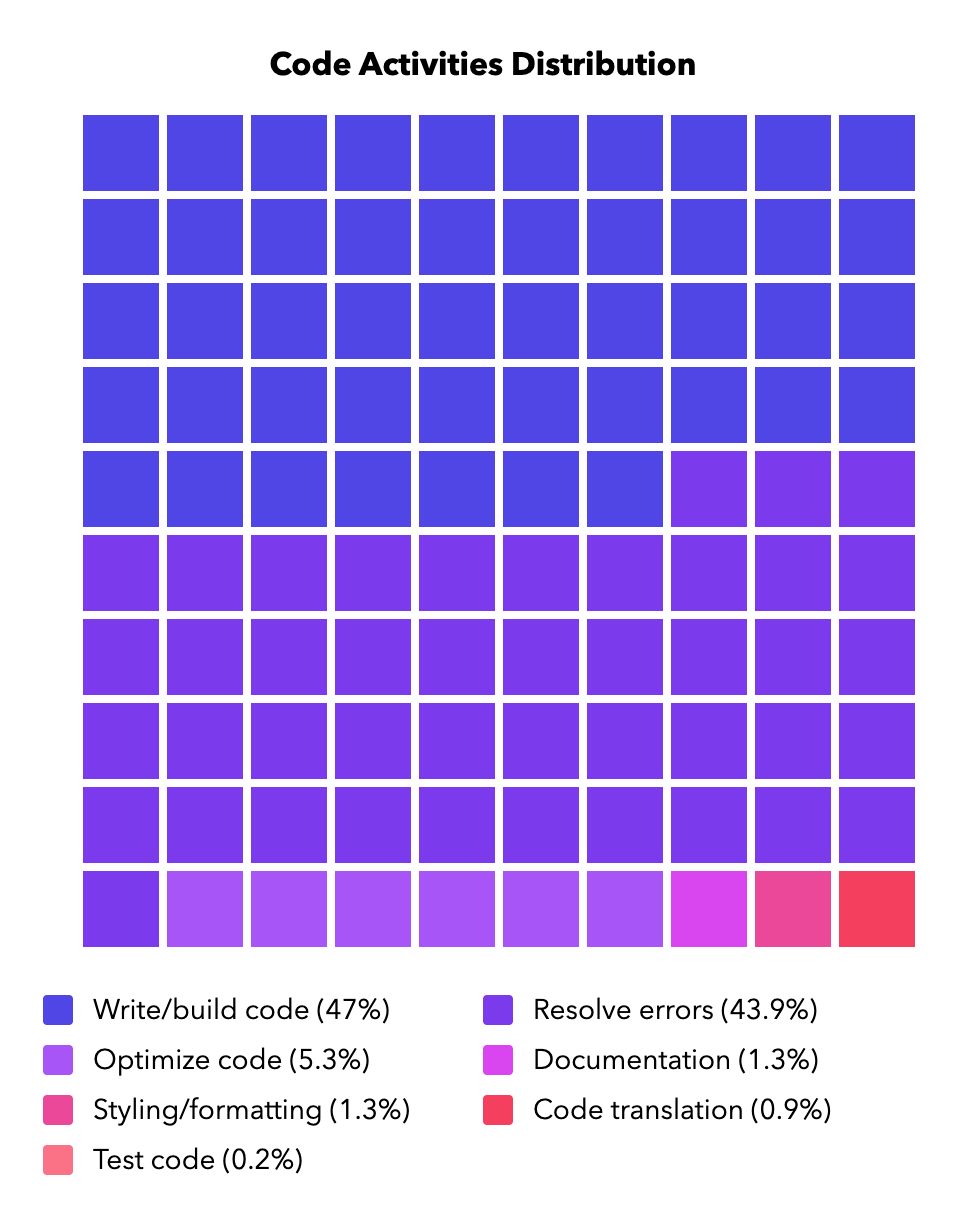
What kind of edits are people trying to make? We find users write prompts for code edits in multiple languages, predominantly English but also in Russian, Chinese, and Spanish. Users typically write prompts using informal language and the prompts are typically directed towards addressing a specific goal. The distribution can be found in Figure 5.
The main categories include:
- Resolve errors
- E.g., “fix the syntax please”, “Cannot read properties of null (reading ‘image’)”
- Optimize code
- E.g., “create a function to validate emailid and phone using regular expression”, “add style to pokemon-image”
- Write code or build on existing code
- E.g., “create a node api to send an email”, “create a function to validate emailid and phone using regular expression”
- Code translation
- E.g., “change this to react compound”, “convert this to oops”
- Test code
- E.g., “create test cases”, “validate the input”
- Styling and formatting
- E.g., “make this code beautiful”, “format that to be compatible with .md”
- Documentation and explanation
- E.g., “explain this code”, “add docstring”
What’s next?
We’re still actively collecting votes for code edits and will continue with deeper analysis in the future. We’re also looking into evaluating methods other than code completions and code edits.
In general, we are always looking to improve Copilot Arena. Ping us to get involved!
Citation
@misc{chi2024copilot,
title={Copilot Arena},
author={Wayne Chi and Valerie Chen and Wei-Lin Chiang and Anastasios N. Angelopoulos and Naman Jain and Tianjun Zhang and Ion Stoica and Chris Donahue and Ameet Talwalkar}
year={2024},
}