Introducing the Search Arena: Evaluating Search-Enabled AI

Authors
Mihran Miroyan*
Tsung-Han Wu*
Logan King
Tianle Li
Anastasios N. Angelopoulos
Wei-Lin Chiang
Narges Norouzi
Joseph E. Gonzalez
TL;DR
- We introduce Search Arena, a crowdsourced in-the-wild evaluation platform for search-augmented LLM systems based on human preference. Unlike LM-Arena or SimpleQA, our data focuses on current events and diverse real-world use cases (see Sec. 1).
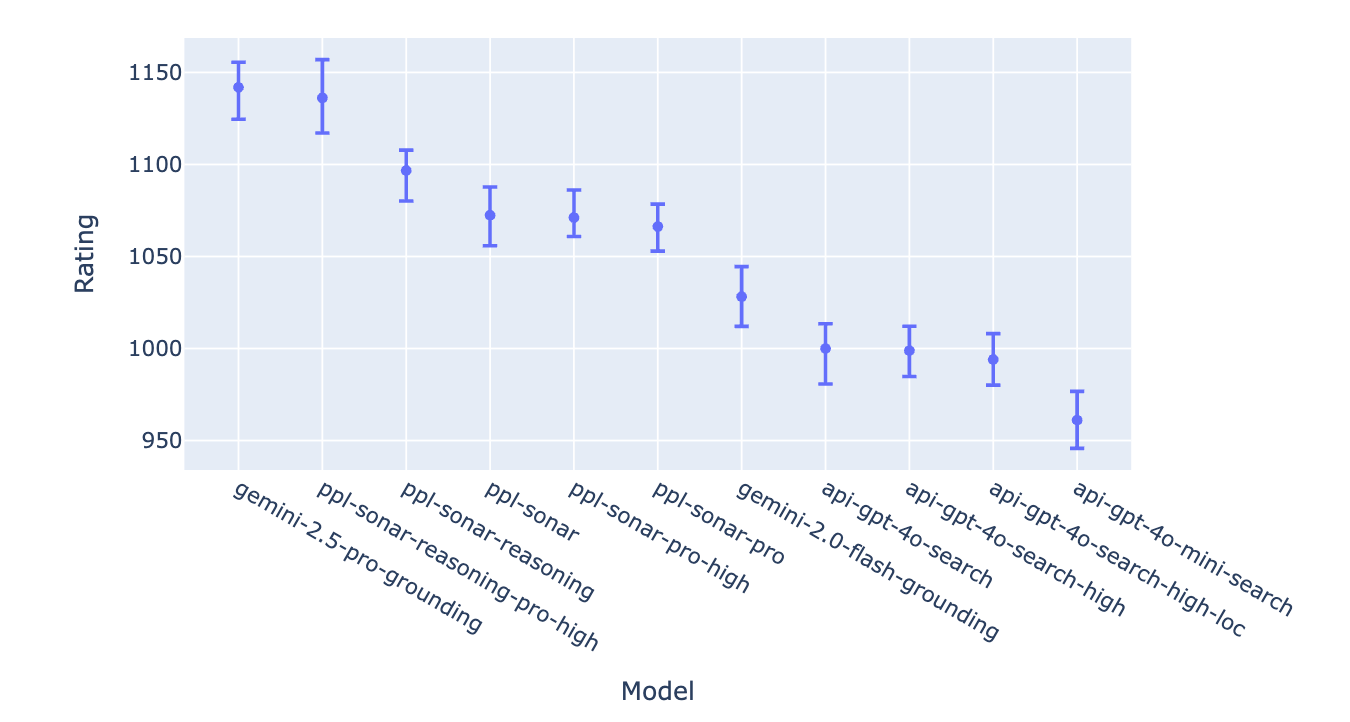
- Based on 7k human votes (03/18–04/13), Gemini-2.5-Pro-Grounding and Perplexity-Sonar-Reasoning-Pro are at the top, followed by the rest of Perplexity’s Sonar models, Gemini-2.0-Flash-Grounding, and OpenAI’s web search API models. Standardizing citation styles had minimal effect on rankings (see Sec. 2).
- Three features show strong positive correlation with human preference: response length, citation count, and citing specific web sources like YouTube and online forum/blogs (see Sec. 3).
- We open-sourced our dataset (🤗 search-arena-7k) and code (⚙️ Colab notebook) for leaderboard analysis. Try 🌐 Search Arena and see Sec. 4 for what’s next.
1. Why Search Arena?
Web search is undergoing a major transformation. Search-augmented LLM systems integrate dynamic real-time web data with the reasoning, problem-solving, and question-answering capabilities of LLMs. These systems go beyond traditional retrieval, enabling richer human–web interaction. The rise of models like Perplexity’s Sonar series, OpenAI’s GPT-Search, and Google’s Gemini-Grounding highlights the growing impact of search-augmented LLM systems.
But how should these systems be evaluated? Static benchmarks like SimpleQA focus on factual accuracy on challenging questions, but that’s only one piece. These systems are used for diverse tasks—coding, research, recommendations—so evaluations must also consider how they retrieve, process, and present information from the web. Understanding this requires studying how humans use and evaluate these systems in the wild.
To this end, we developed search arena, aiming to (1) enable crowd-sourced evaluation of search-augmented LLMs and (2) release a diverse, in-the-wild dataset of user–system interactions.
Since our initial launch on March 18th, we’ve collected over 11k votes across 10+ models. We then filtered this data to construct 7k battles with user votes (🤗 search-arena-7k) and calculated the leaderboard with this ⚙️ Colab notebook. Below, we provide details on the collected data and the supported models.
A. Data
Data Filtering and Citation Style Control. Each model provider uses a unique inline citation style, which can potentially compromise model anonymity. However, citation formatting impacts how information is presented to and processed by the user, impacting their final votes. To balance these considerations, we introduced “style randomization”: responses are displayed either in a standardized format or in the original format (i.e., the citation style agreed upon with each model provider).
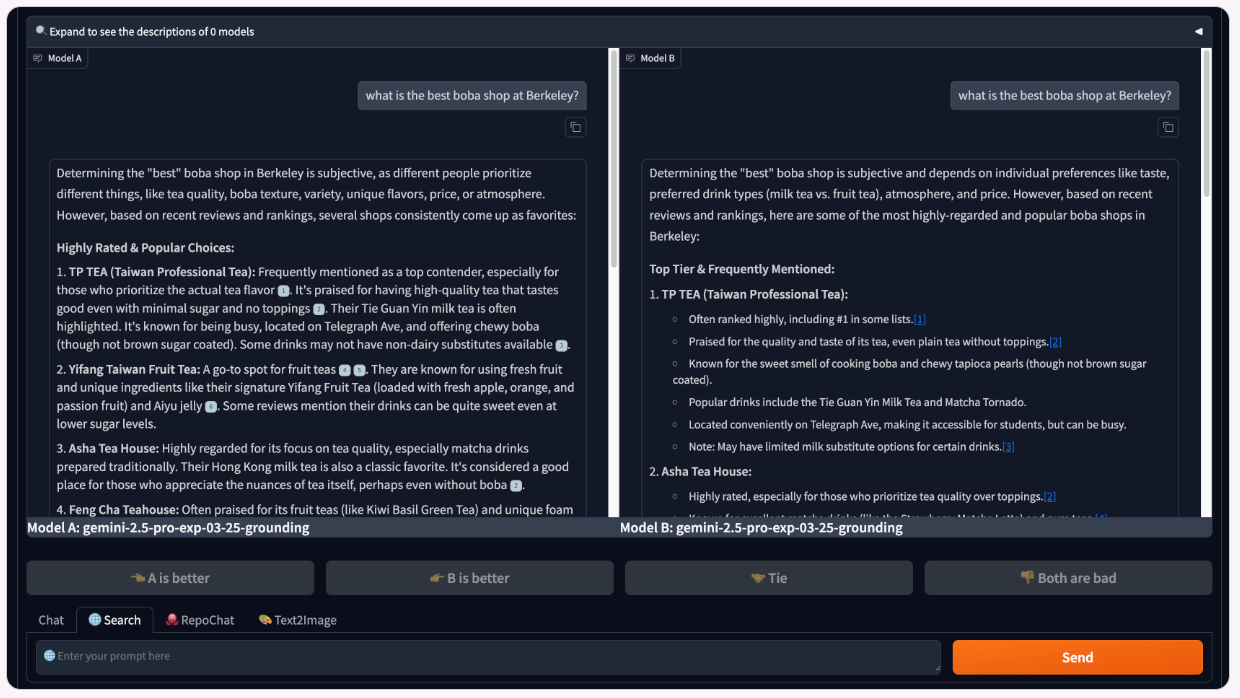
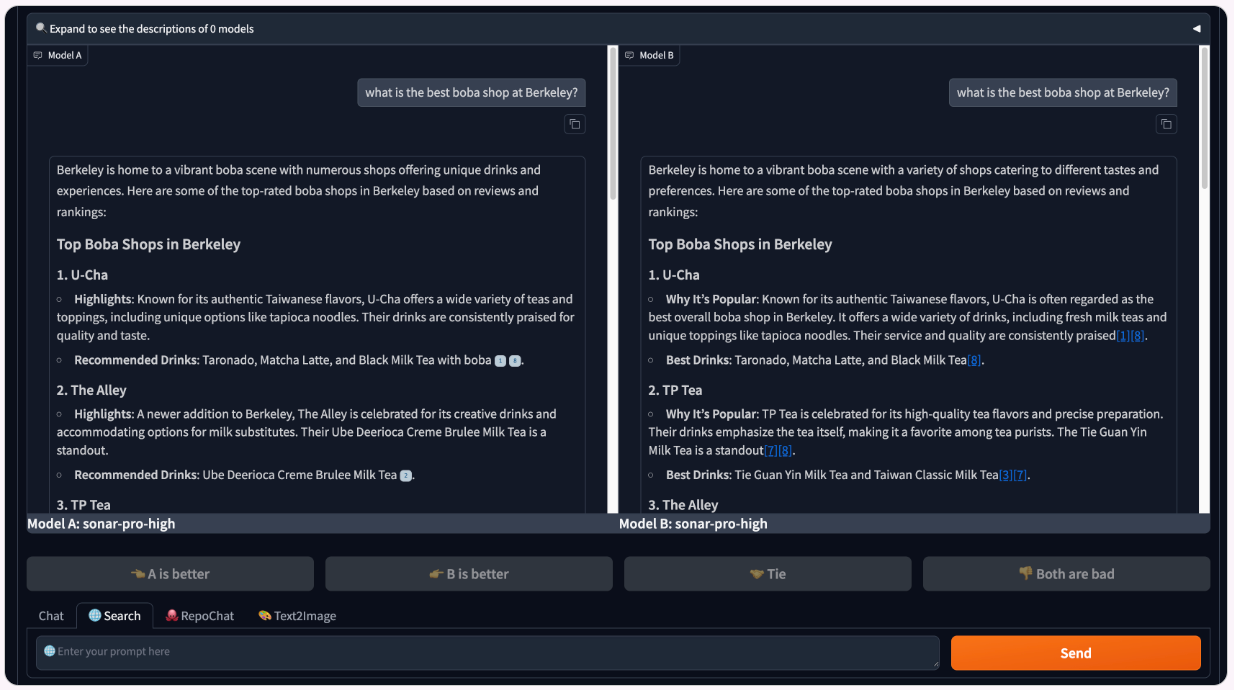
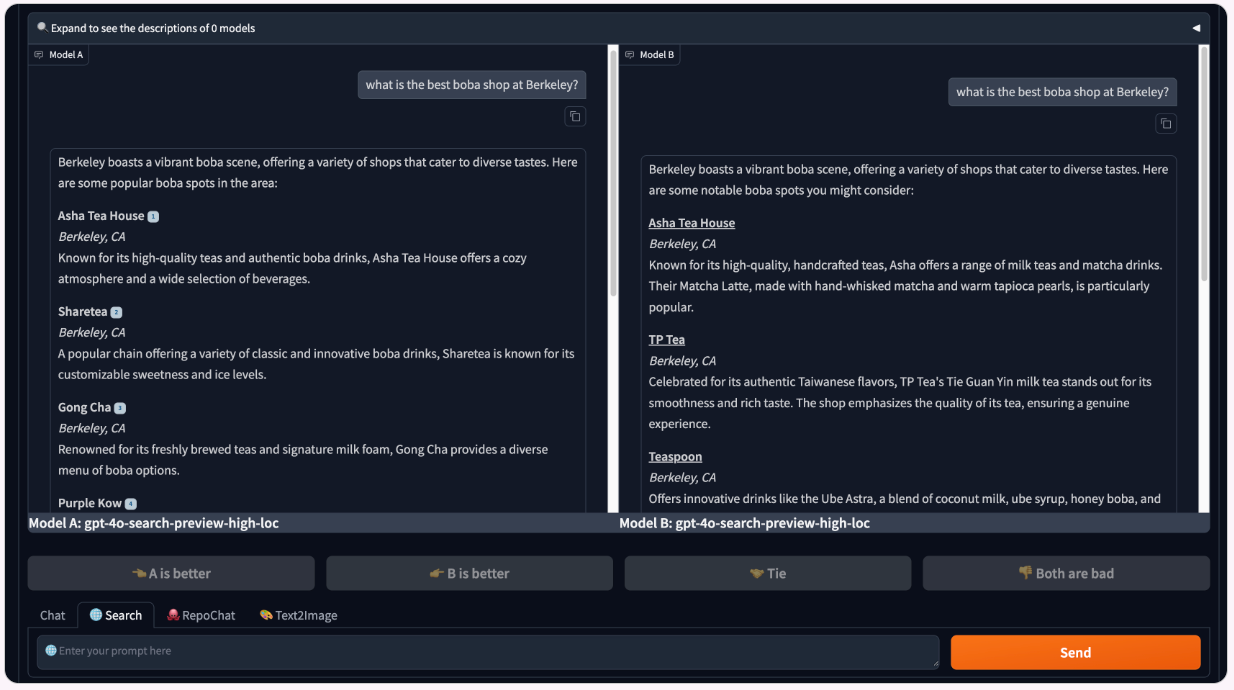
This approach mitigates de-anonymization while allowing us to analyze how citation style impacts user votes (see the citation analyses subsection here). After updating and standardizing citation styles in collaboration with providers, we filtered the dataset to include only battles with the updated styles, resulting in ~7,000 clean samples for leaderboard calculation and further analysis.
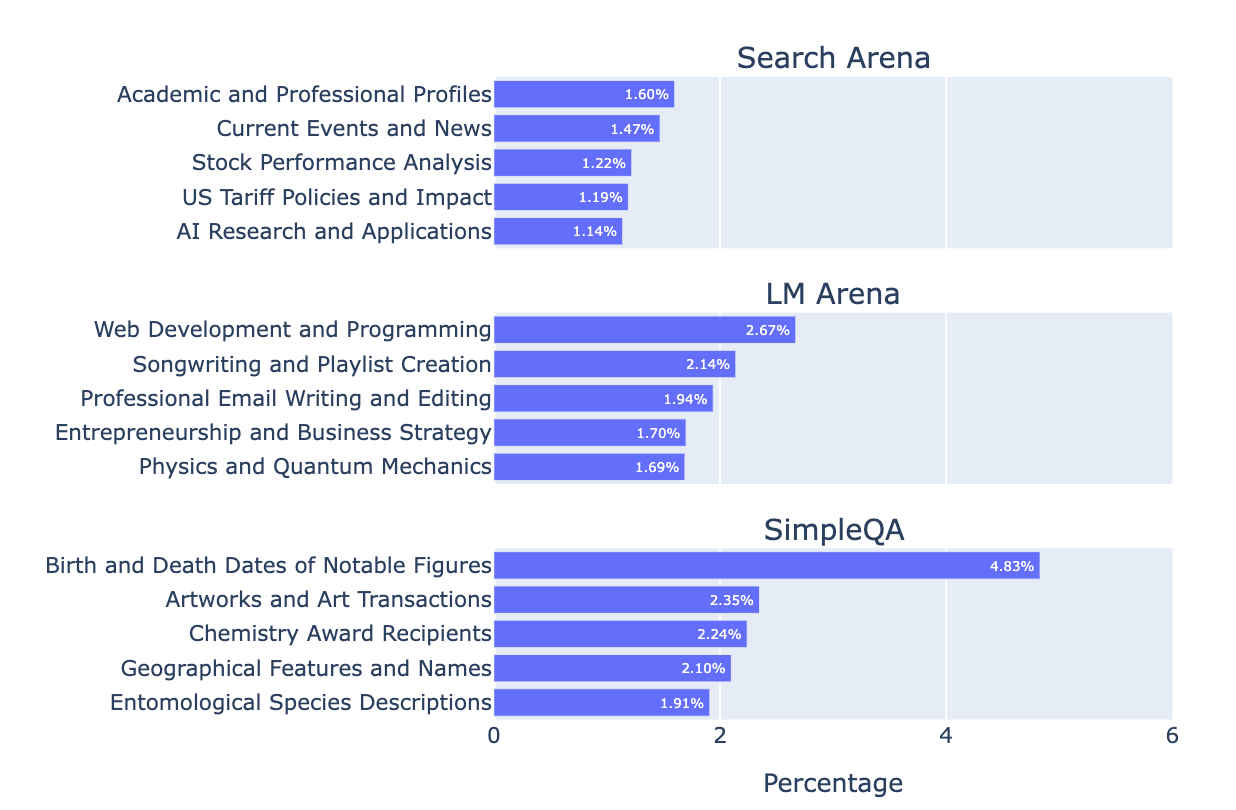
Comparison to Existing Benchmarks. To highlight what makes Search Arena unique, we compare our collected data to LM-Arena and SimpleQA. As shown in Fig. 2, Search Arena prompts focus more on current events, while LM-Arena emphasizes coding/writing, and SimpleQA targets narrow factual questions (e.g., dates, names, specific domains). Tab. 1 shows that Search Arena features longer prompts, longer responses, more turns, and more languages compared to SimpleQA—closer to natural user interactions seen in LM-Arena.

B. Models
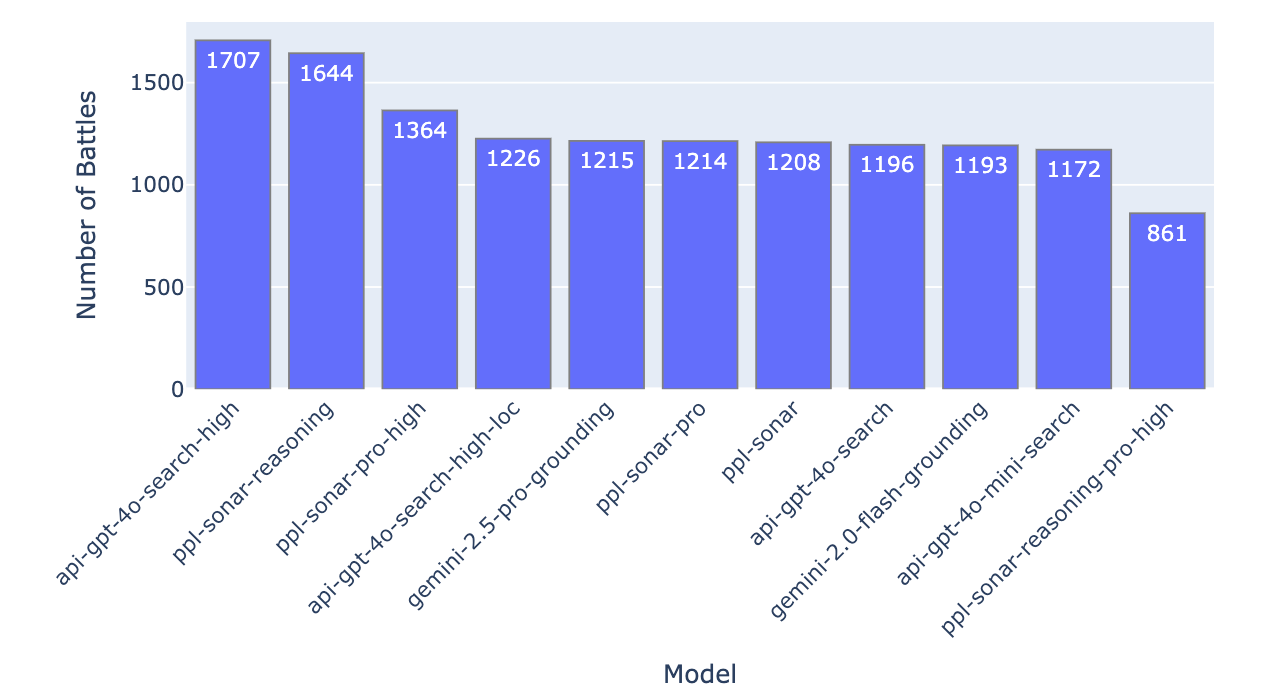
Search Arena currently supports 11 models from three providers: Perplexity, Gemini, and OpenAI. Unless specified otherwise, we treat the same model with different citation styles (original vs. standardized) as a single model. Fig. 3 shows the number of battles collected per model used in this iteration of the leaderboard.
By default, we use each provider’s standard API settings. For Perplexity and OpenAI, this includes setting the search_context_size parameter to medium, which controls how much web content is retrieved and passed to the model. We also explore specific features by changing the default settings: (1) For OpenAI, we test their geolocation feature in one model variant by passing a country code extracted from the user’s IP address. (2) For Perplexity and OpenAI, we include variants with search_context_size set to high. Below is the list of models currently supported in Search Arena:

†We evaluate OpenAI’s web search API, which is different from the search feature in the ChatGPT product.
2. Leaderboard
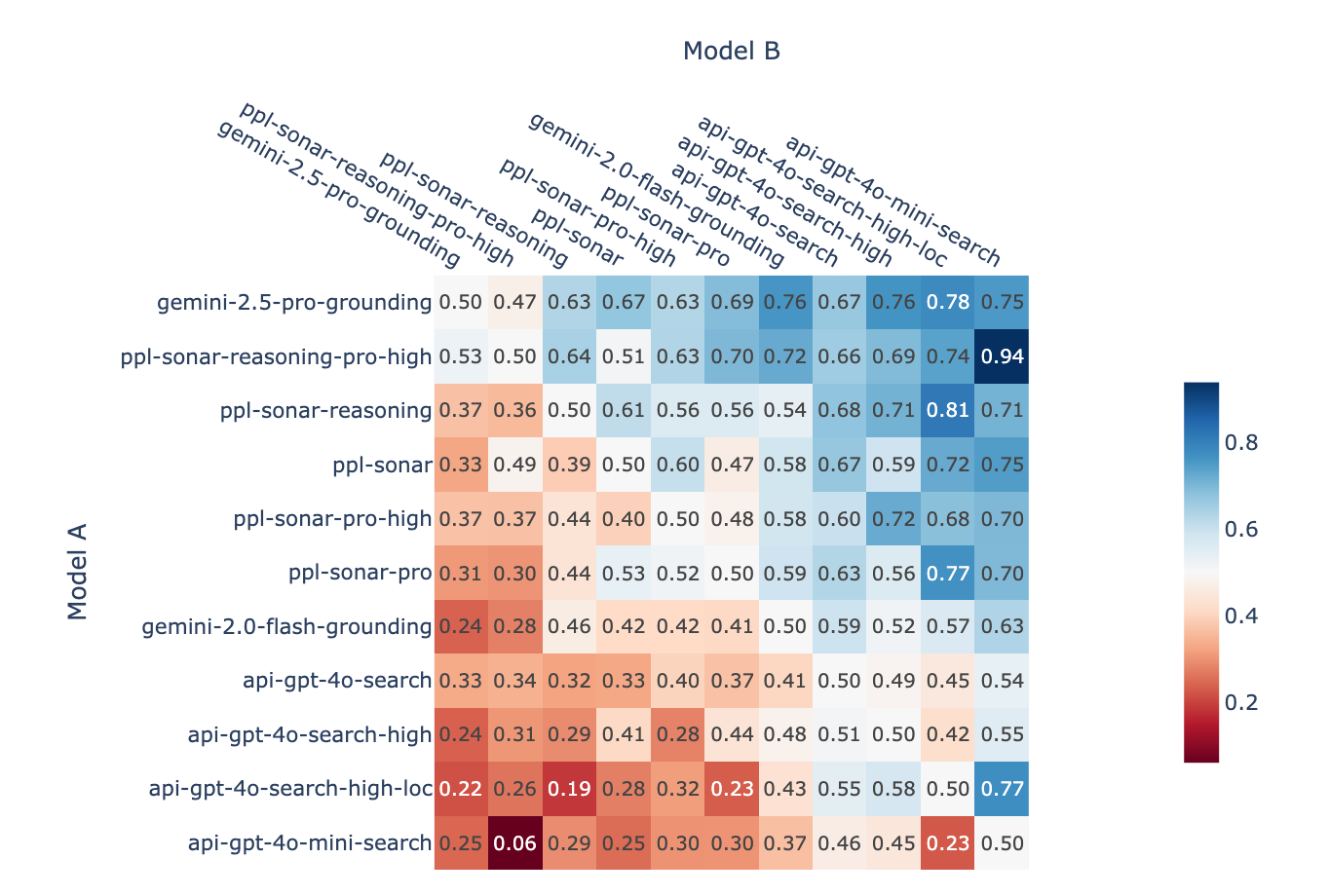
We begin by analyzing pairwise win rates—i.e., the proportion of wins of model A over model B in head-to-head battles. This provides a direct view of model performance differences without aggregating scores. The results are shown in Fig. 4, along with the following observations:
gemini-2.5-pro-groundingandppl-sonar-reasoning-pro-highoutperform all other models by a large margin. In direct head-to-head battlesppl-sonar-reasoning-pro-highhas a slight advantage (53% win rate).ppl-sonar-reasoningoutperforms the rest of Perplexity’s models. There’s no clear difference betweenppl-sonar-proandppl-sonar-pro-high(52%/48% win rate), and evenppl-sonarbeatsppl-sonar-pro-high(60% win rate). This suggests that increasing search context does not necessarily improve performance and may even degrade it.- Within OpenAI’s models, larger search context does not significantly improve performance (
api-gpt-4o-searchvsapi-gpt-4o-search-high). While adding user location improves performance in head-to-head battles (58% win rate ofapi-gpt-4o-search-high-locoverapi-gpt-4o-search-high), location-enabled version ranks lower in the leaderboard.
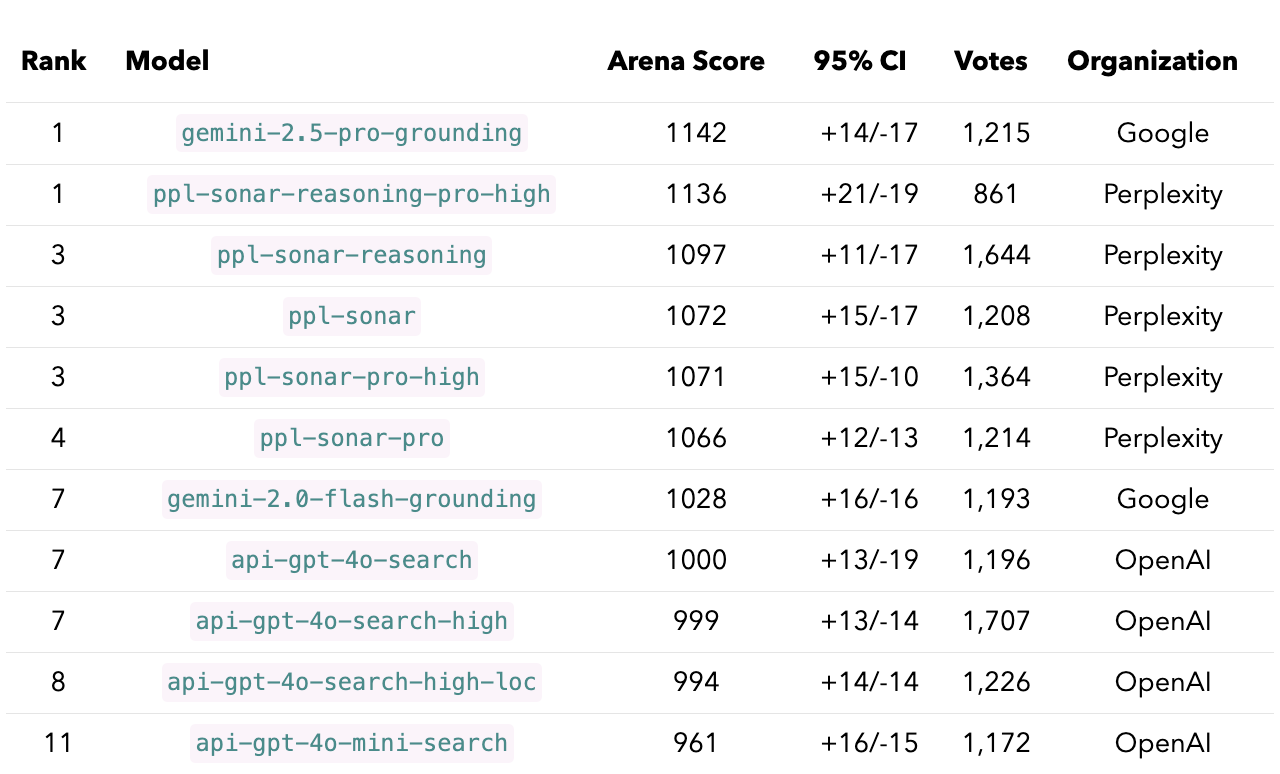
tie and tie (bothbad) votes.Now we build the leaderboard! Consistent with LM Arena, we apply the Bradley-Terry (BT) model to compute model scores. The resulting BT coefficients are then translated to Elo scale, with the final model scores and rankings displayed in Fig. 1 and Tab. 3. The confidence intervals are still wide, which means the leaderboard hasn’t fully settled and there’s still some uncertainty. But clear performance trends are already starting to emerge. Consistent with the pairwise win rate analysis in the previous section, gemini-2.5-pro-grounding and ppl-sonar-reasoning-pro-high top the leaderboard by a substantial margin. They are followed by models from the ppl-sonar family, with ppl-sonar-reasoning leading the group. Then comes gemini-2.0-flash-grounding, and finally OpenAI models with api-gpt-4o-search based models outperforming api-gpt-4o-mini-search. Generally, users prefer responses from reasoning models (top 3 on the leaderboard).
Citation Style Analysis
Having calculated the main leaderboard, we can now analyze the effect of citation style on user votes and model rankings. For each battle, we record model A’s and B’s citation style — original (agreed upon with the providers) vs standardized.
First, following the method in (Li et al., 2024), we apply style control and use the citation style indicator variable (1 if standardized, 0 otherwise) as an additional feature in the BT model. The resulting model scores and rankings do not change significantly from the main leaderboard. Although the leaderboard does not change, the corresponding coefficient is positive (0.044) and statistically significant (p<0.05), implying that standardization of citation style has a positive impact on model score.
We further investigate the effect of citation style on model performance, by treating each combination of model and citation style as a distinct model (e.g., api-gpt-4o-search with original style will be different from api-gpt-4o-search with standardized citation style). Fig. 5 shows the change in the arena score between the two styles of each model. Overall, we observe increase or no change in score with standardized citations across all models except gemini-2.0-flash. However, the differences remain within the confidence intervals (CI), and we will continue collecting data to assess whether the trend converges toward statistical significance.
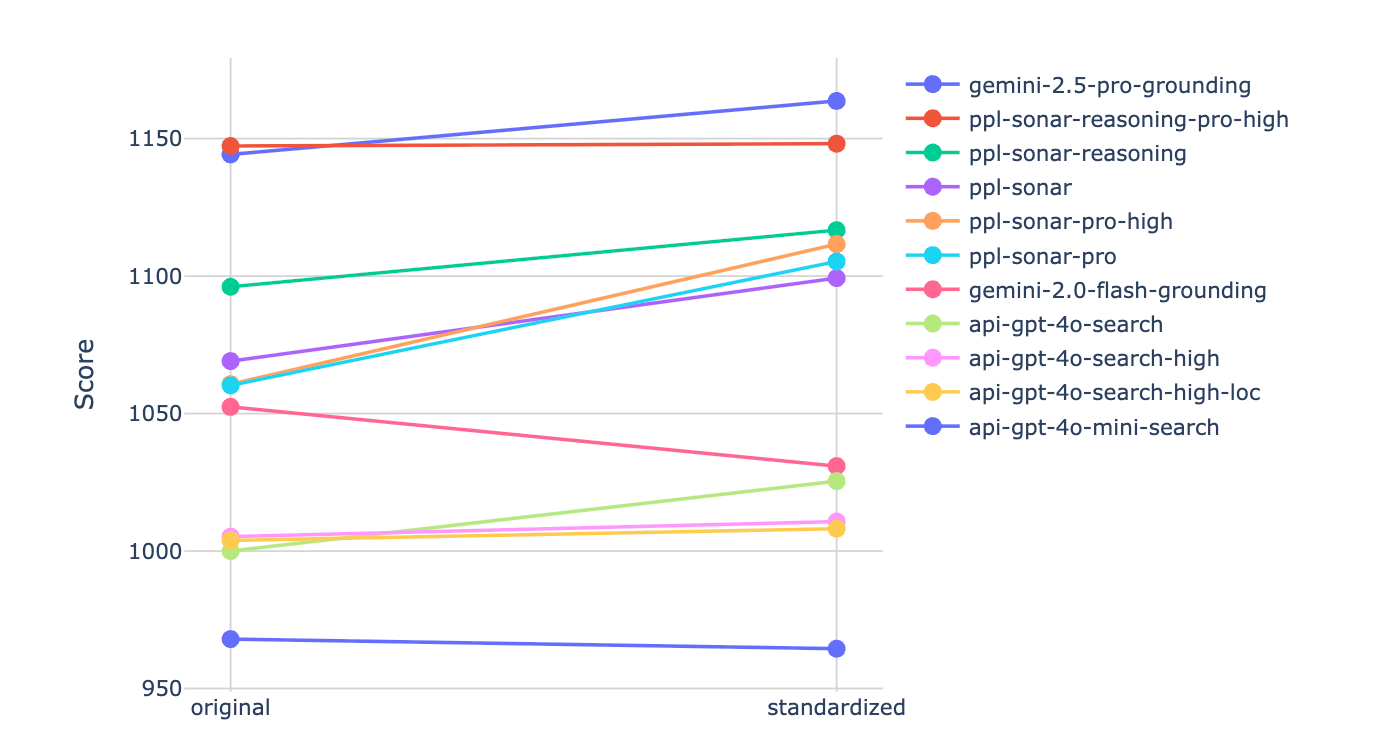
3. Three Secrets Behind a WIN
After reviewing the leaderboard—and showing that the citation style doesn’t impact results all that much—you might be wondering: What features contribute to the model’s win rate?
To answer this, we used the framework in (Zhong et al., 2022), a method that automatically proposes and tests hypotheses to identify key differences between two groups of natural language texts—in this case, human-preferred and rejected model outputs. In our implementation, we asked the model to generate 25 hypotheses and evaluate them, leading to the discovery of three distinguishing factors with statistically significant p-values, shown in Tab. 4.

Model Characteristics
Guided by the above findings, we analyze how these features vary across models and model families.
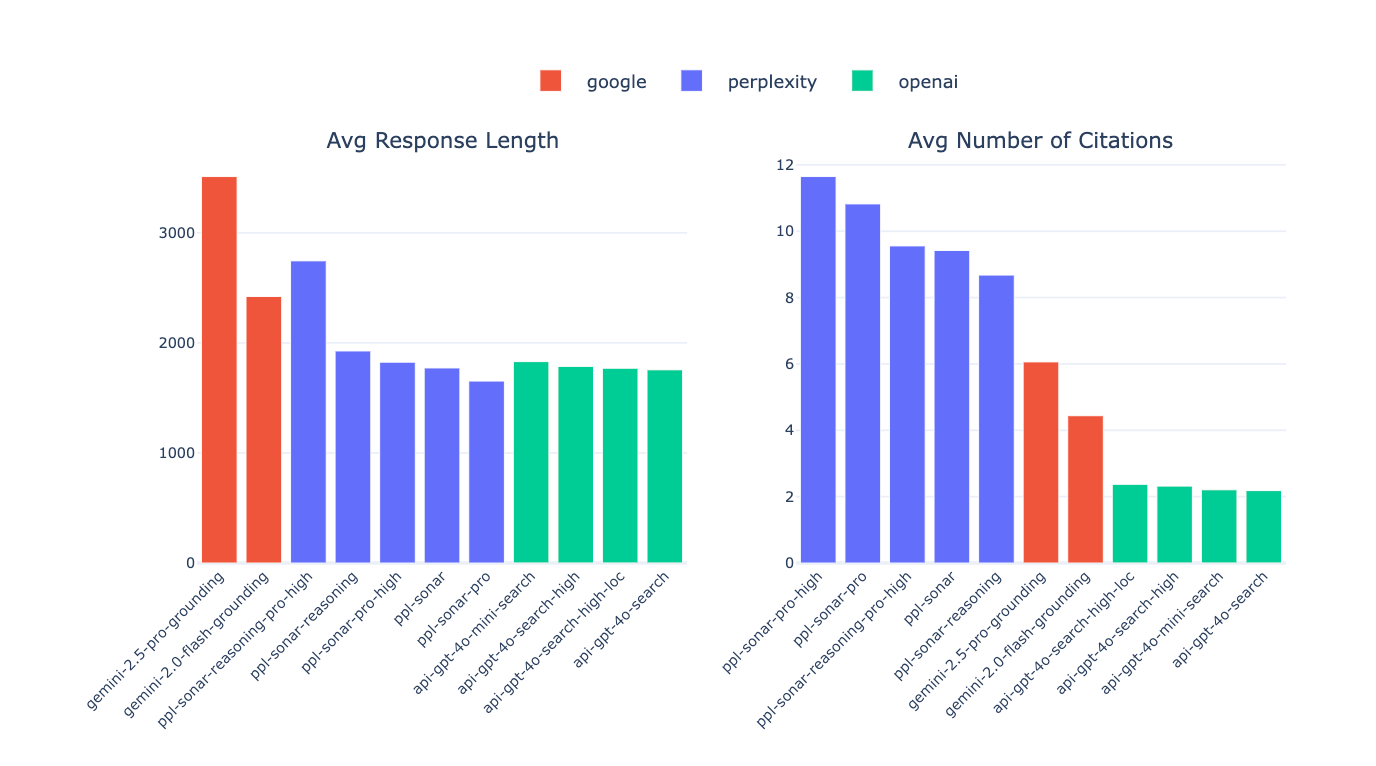
Fig. 6 (left) shows the distribution of average response length across models. Gemini models are generally the most verbose—gemini-2.5-pro-grounding, in particular, produces responses nearly twice as long as most Perplexity or OpenAI models. Within the Perplexity and OpenAI families, response length is relatively consistent, with the exception of ppl-sonar-reasoning-pro-high. Fig. 6 (right) shows the average number of citations per response. Sonar models cite the most, with ppl-sonar-pro-high citing 2-3x more than Gemini models. OpenAI models cite the fewest sources (2-2.5) with little variation within the group.
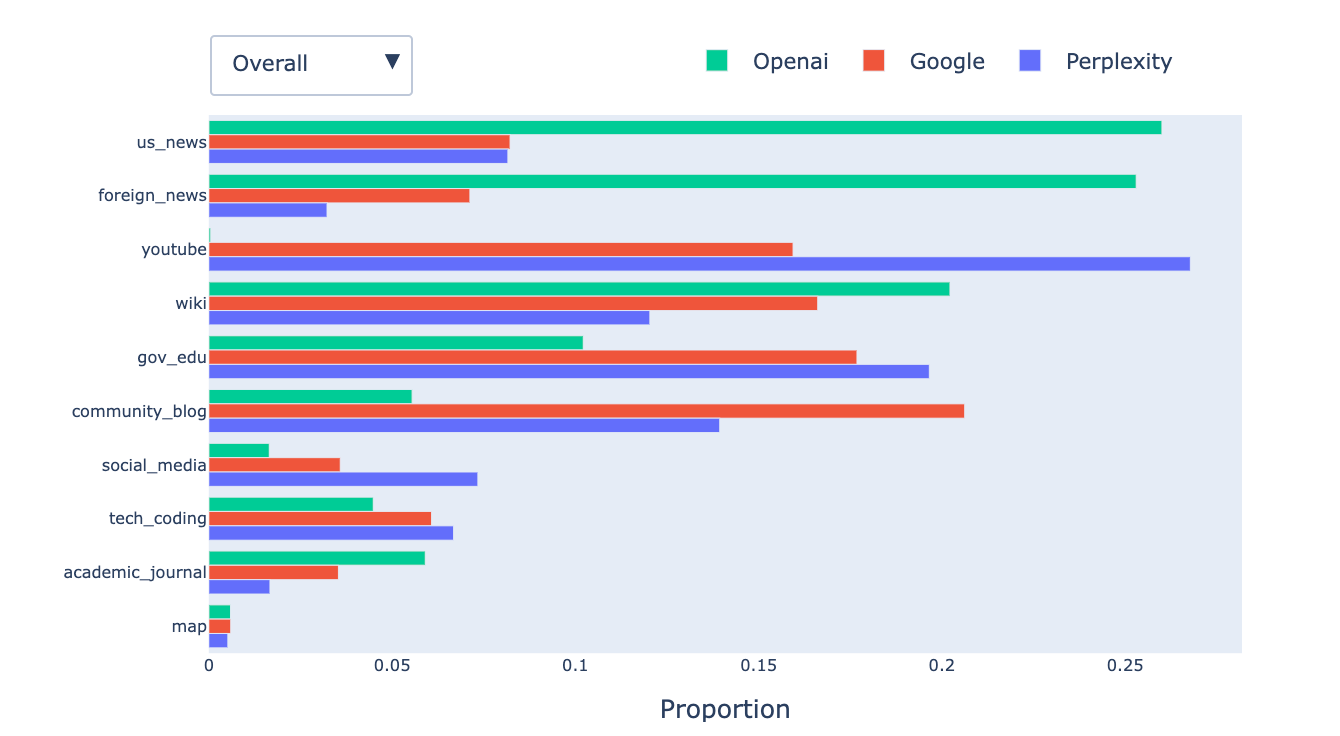
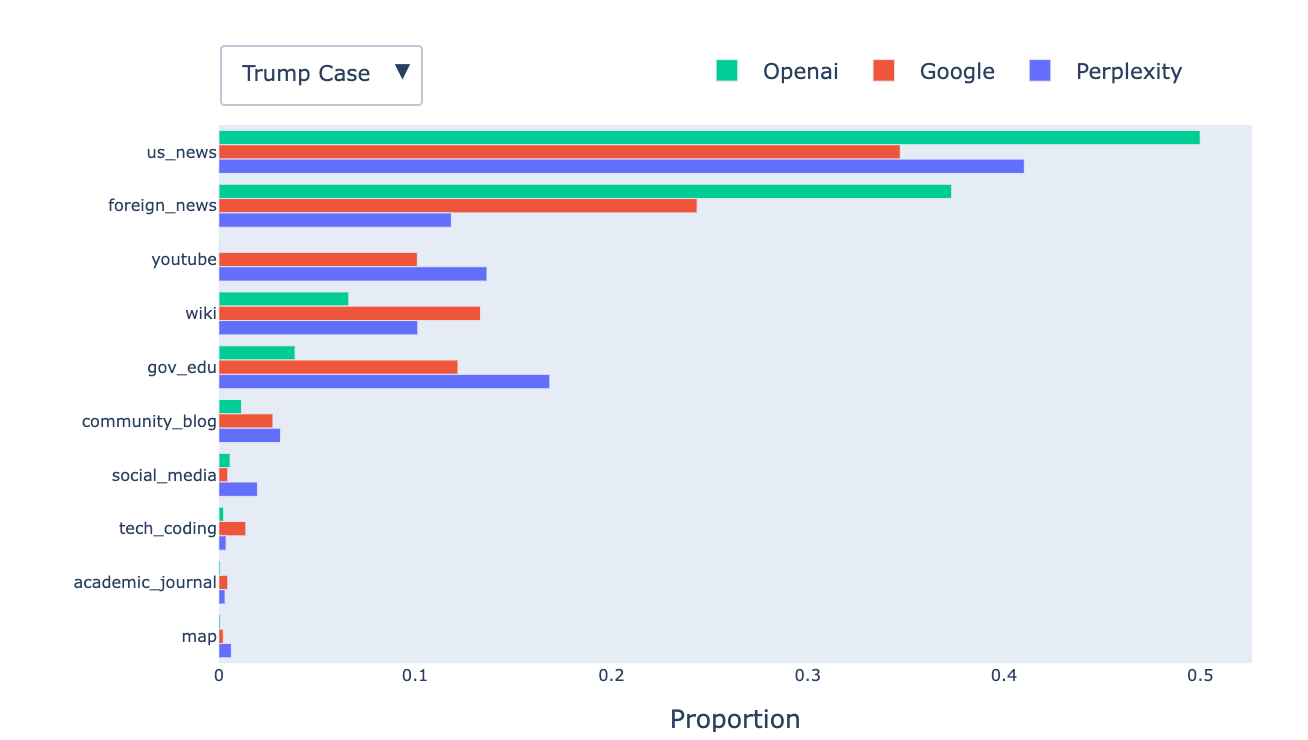
In addition to number of citations and response length, we also study the common source domains cited by each model. We categorize retrieved URLs into ten types: YouTube, News (U.S. and foreign), Community & Blogs (e.g., Reddit, Medium), Wikipedia, Tech & Coding (e.g., Stack Overflow, GitHub), Government & Education, Social Media, Maps, and Academic Journals. Fig. 7 shows the domain distribution across providers in two settings: (1) all conversations, and (2) a filtered subset focused on Trump-related prompts. The case study helps examine how models behave when responding to queries on current events. Here are three interesting findings:
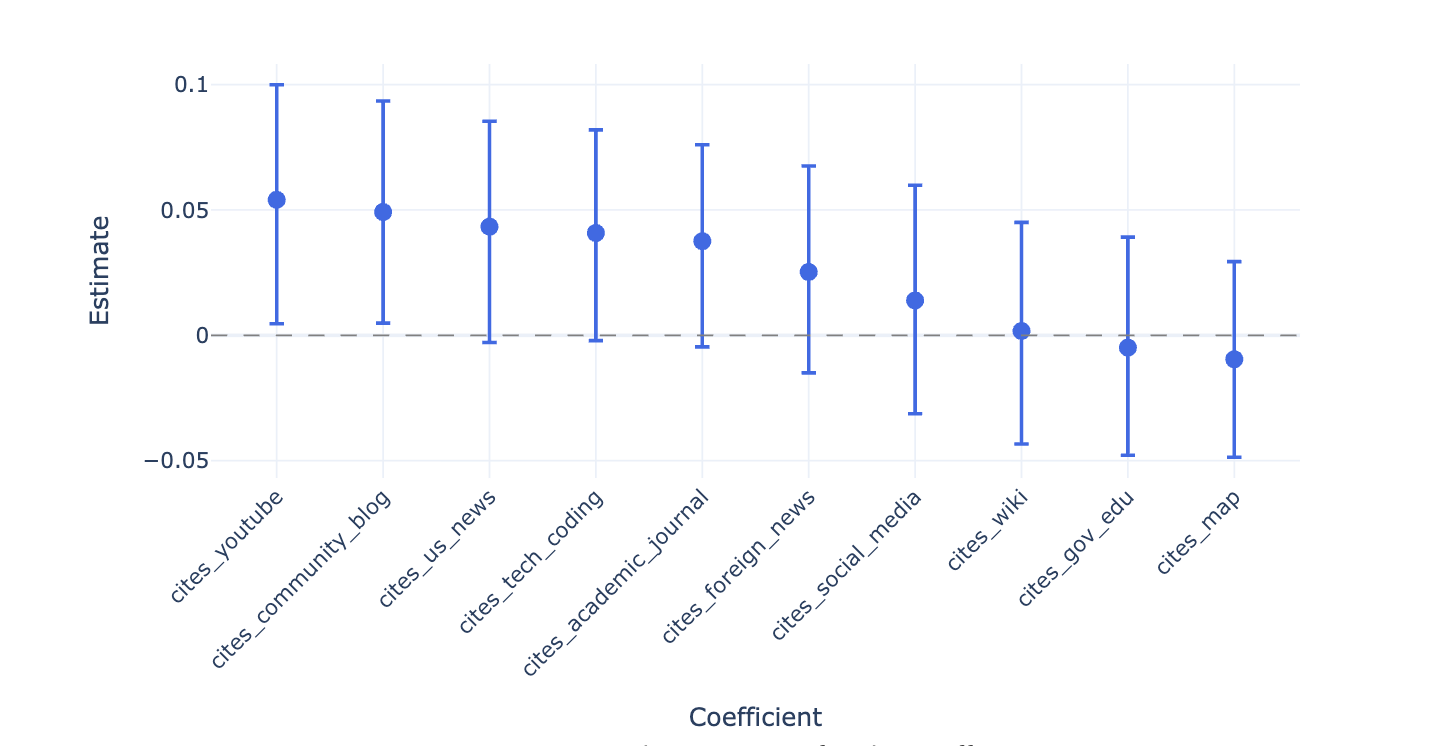
- All models favor authoritative sources (e.g., Wikipedia,
.edu,.govdomains). - OpenAI models heavily cite news sources—51.3% overall and 87.3% for Trump-related prompts.
- Gemini prefers community/blog content, whereas Perplexity frequently cites YouTube. Perplexity also strongly favors U.S. news sources over foreign ones (3x more often).
Control Experiments
After analyzing model characteristics such as response length, citation count, and citation sources, we revisited the Bradley-Terry model with these features as additional control variables (Li et al., 2024). Below are some findings when controlling for different subsets of control features:
- Response length: Controlling for response length yields a positive and statistically significant coefficient (0.255, p < 0.05), indicating that users prefer more verbose responses.
- Number of citations: Controlling for citation count also results in a positive and significant coefficient (0.234, p < 0.05), suggesting a preference for responses with more cited sources.
- Citation source categories: As shown in Fig. 8, citations from community platforms (e.g., Reddit, Quora) and YouTube have statistically significant positive effects on user votes. The remaining categories have insignificant coefficients.
- Joint controls: When controlling for all features, only response length and citation count remain statistically significant.
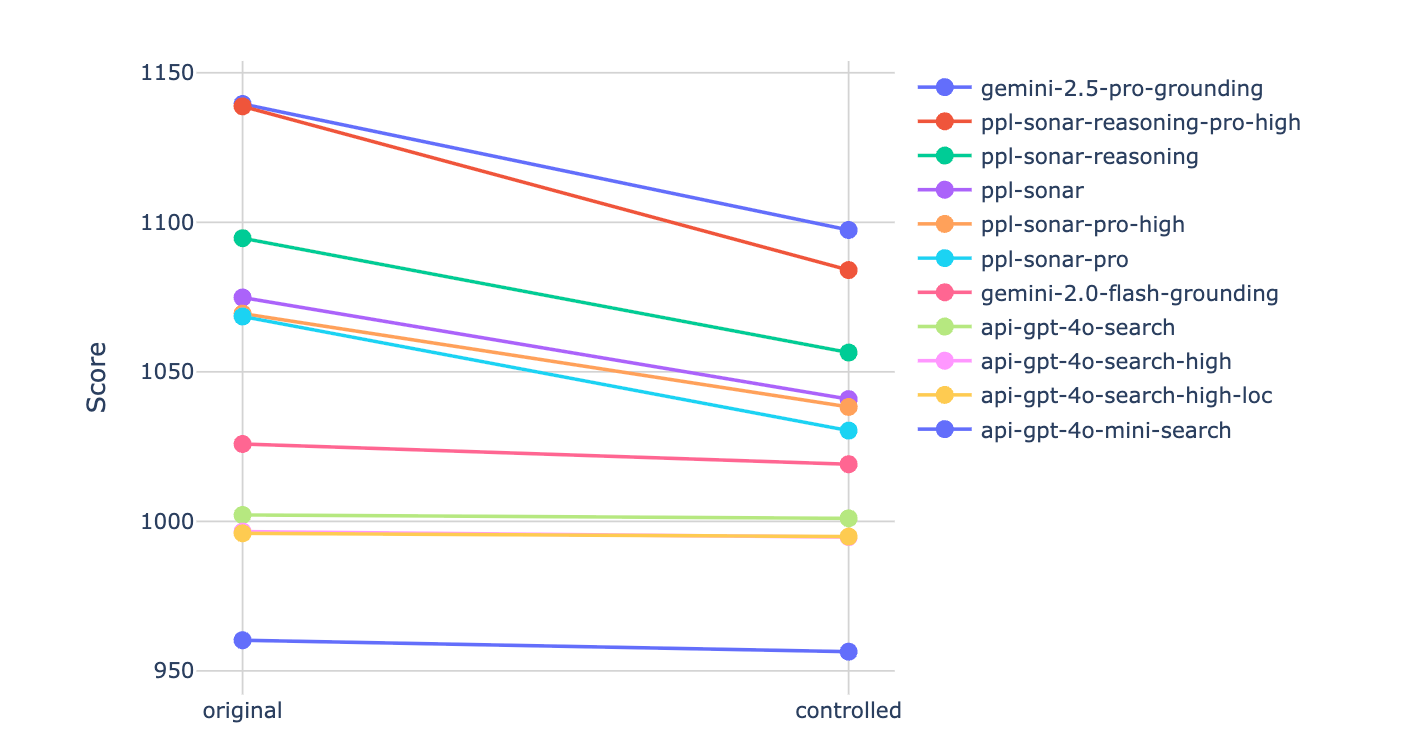
Finally, we used all previously described features to construct a controlled leaderboard. Fig. 9 compares the original and adjusted arena scores after controlling for response length, citation count, and cited sources. Interestingly, when using all these features as control variables, the top six models all show a reduction in score, while the remaining models are largely unaffected. This narrows the gap between gemini-2.0-flash-grounding and non-reasoning Perplexity models. Tab. 5 shows model rankings when controlling for different subsets of these features:
- Controlling for response length,
ppl-sonar-reasoningshares the first rank withgemini-2.5-pro-groundingandppl-sonar-reasoning-pro-high. The difference between (1)sonar-proand other non-reasoning sonar models as well (2)api-gpt-4o-search-highandapi-gpt-4o-search-high-loc, disappear. - When controlling for the number of citations, model rankings converge (i.e., multiple models share the same rank), suggesting that the number of citations is a significant factor impacting differences across models and the resulting rankings.
- Controlling for cited domains has minimal effect on model rankings.
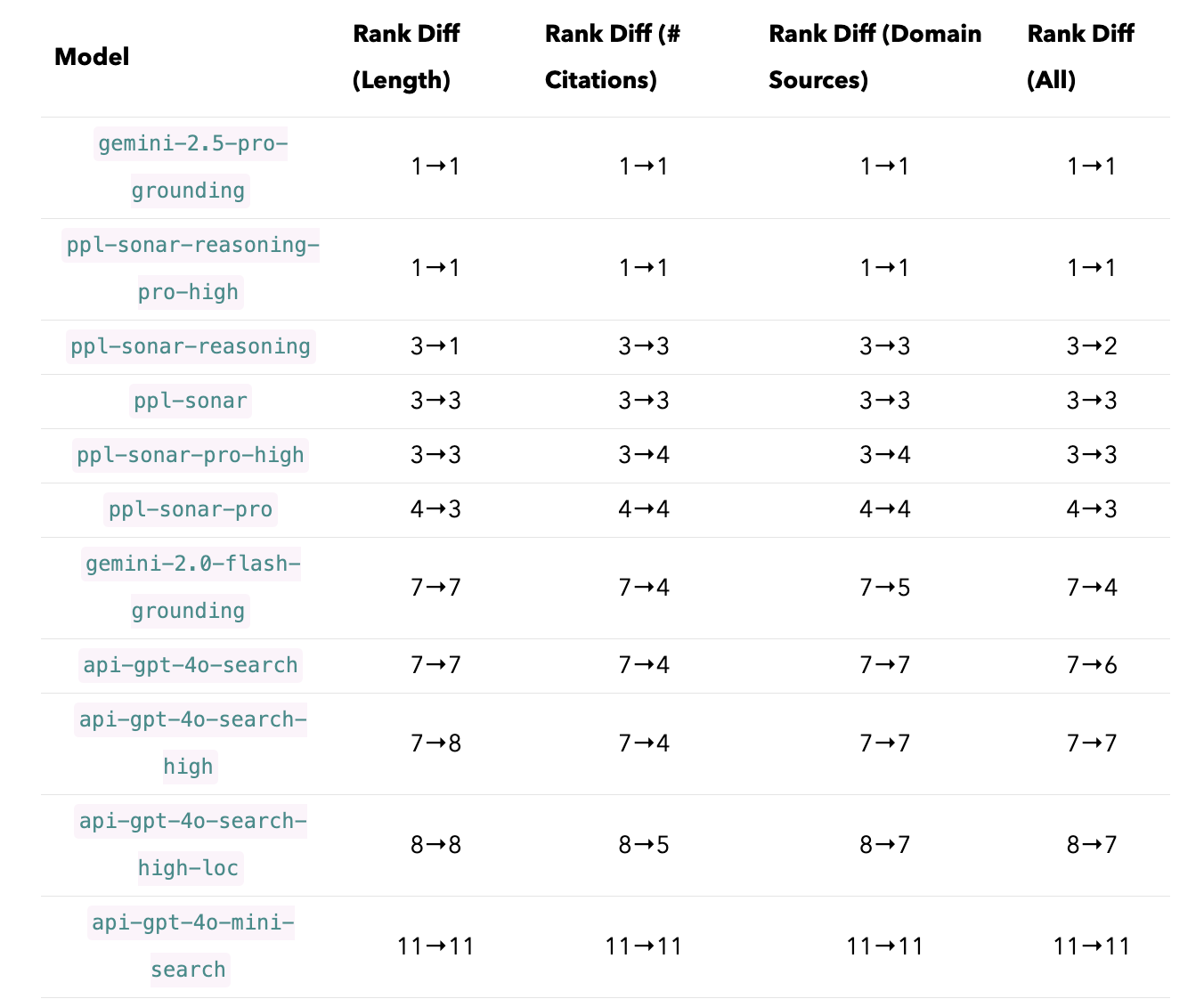
4. Conclusion & What’s Next
As search-augmented LLMs become increasingly popular, Search Arena provides a real-time, in-the-wild evaluation platform driven by crowdsourced human feedback. Unlike static QA benchmarks, our dataset emphasizes current events and diverse real-world queries, offering a more realistic view of how users interact with these systems. Using 7k human votes, we found that Gemini-2.5-Pro-Grounding and Perplexity-Sonar-Reasoning-Pro-High share the first rank in the leaderboard. User preferences are positively correlated with response length, number of citations, and citation sources. Citation formatting, surprisingly, had minimal impact.
We have open-sourced our data (🤗 search-arena-7k) and analysis code (⚙️ Colab notebook). Try 🌐 Search Arena now and see what’s next:
- Open participation: We are inviting model submissions from researchers and industry, and encouraging public voting.
- Cross-task evaluation: How well do search models handle general questions? Can LLMs manage search-intensive tasks?
- Raise the bar for open models: Can simple wrappers with search engine/scraping + tools like ReAct and function calling make open models competitive?
Citation
@misc{searcharena2025,
title = {Introducing the Search Arena: Evaluating Search-Enabled AI},
url = {https://blog.lmarena.ai/blog/2025/search-arena/},
author = {Mihran Miroyan*, Tsung-Han Wu*, Logan Kenneth King, Tianle Li, Anastasios N. Angelopoulos, Wei-Lin Chiang, Narges Norouzi, Joseph E. Gonzalez},
month = {April},
year = {2025}
}
@inproceedings{chiang2024chatbot,
title={Chatbot arena: An open platform for evaluating llms by human preference},
author={Chiang, Wei-Lin and Zheng, Lianmin and Sheng, Ying and Angelopoulos, Anastasios Nikolas and Li, Tianle and Li, Dacheng and Zhu, Banghua and Zhang, Hao and Jordan, Michael and Gonzalez, Joseph E and others},
booktitle={Forty-first International Conference on Machine Learning},
year={2024}
}